도메인 모델링 첫날 — B2B SaaS의 핵심 엔티티 정의하기
📚 NestJS + Refine 풀스택 트러블슈팅 시리즈 (63편)
B2B SaaS 백엔드를 만들면서 도메인 모델링을 시작한 이야기. 마스터 문서 2,486줄을 쓰고, 유즈케이스를 정의하고, 핵심 엔티티 관계를 잡아가는 과정을 기록합니다.
💡 Tip. 바쁜 현대인들을 위한 본문 요약
코드 한 줄 안 치고 9일을 보냈다. 마스터 문서 2,486줄, 유즈케이스 정의, 엔티티 관계도 — 전부 문서였다. “빨리 코딩하고 싶다”는 욕구를 참고 도메인을 먼저 이해한 덕에, 나중에 v2.0으로 갈아엎을 때도 이 문서가 기준이 됐다. 도메인 모델링은 코딩 전에 하는 게 맞다.
🗺️ 코드 전에 지도를 그린다
nest new를 치고 첫 커밋을 올린 게 11월 18일이었다.
그런데 두 번째 커밋은 11월 27일에야 올라왔다. 9일 동안 코드를 한 줄도 안 쳤다. 대신 문서를 썼다. 엄청 많이.
왜 그랬냐면, 만들려는 서비스의 도메인이 생각보다 복잡했기 때문이다. B2B SaaS 플랫폼 — 멀티테넌트에 4가지 역할, 30개 등급, 성과 지표 추적, 적응형 진행 트랙. 머릿속으로 돌려보면 “대충 알겠는데?” 싶지만, 코드로 옮기려고 하면 “이거 어떤 테이블이 어떤 테이블을 참조하지?” 가 끊임없이 나온다.
이전 프로젝트에서 뼈저리게 느꼈다. 설계 없이 코딩에 바로 들어가면, 개발 중간에 “이건 이런 뜻이 아니었는데”가 반복된다. 요구사항이 바뀌는 게 아니라, 처음부터 서로 다르게 이해하고 있었던 거다.
그래서 이번엔 원칙을 하나 세웠다:
코드를 치기 전에 도메인을 완전히 이해한다.
📋 마스터 문서 — 2,486줄의 탄생
클라이언트와의 미팅에서 나온 모든 것을 문서로 옮겼다. 결과물:
docs/마스터.md — 709줄
docs/MVP_EPR_정의.md — 132줄
docs/erd.md — 393줄
docs/필요_정의사항_명확화.md — 1,029줄
docs/우선순위정의.md — 223줄총 2,486줄. 그중에서도 필요_정의사항_명확화.md 1,029줄이 가장 중요했다. 이 문서는 “구현할 때 결정해야 하는 것들”을 전부 리스트업한 거다.
예를 들면 이런 질문들:
- 등급 조정은 실시간으로 할 건가, 배치로 할 건가?
- 진행 트랙 완료 기준은 누적 점수인가, 연속 달성인가?
- 외부 뷰어(보호자) 인증은 토큰 기반인가, 세션 기반인가?
- 작업 묶음(Bundle)이 완료되면 자동으로 다음 묶음을 생성하는가?
- 멀티트랙 전환 시 이전 트랙의 진행 데이터는 보존하는가?
이 결정들을 코딩하면서 하면 코드를 뒤엎게 된다. 미리 하면 코드가 한 방향으로 간다.
문서화의 효과
4개월 후에 회고해보니, 이 9일이 프로젝트에서 가장 가치 있는 시간이었다. 나중에 v2.0으로 전면 재작성할 때도 이 마스터 문서가 기준점이 됐다.
물론, 프로토타입을 보여주면 클라이언트 머릿속에서 새로운 아이디어가 떠오르고 비즈니스 관점 자체가 바뀌는 건 막을 수 없었다. 문서의 한계라기보다 제품 개발의 본질이다. 중요한 건 바뀌더라도 기준점이 있었다는 것. “원래 이렇게 정했는데, 이번에 이렇게 바뀐다”를 추적할 수 있었다.
🧩 핵심 엔티티 도출 — 도메인 분해
마스터 문서를 기반으로 핵심 엔티티를 도출했다. B2B SaaS라서 최상위에 **테넌트(Tenant)**가 있고, 모든 데이터가 테넌트 아래에 격리되는 구조.
1단계: 핵심 엔티티 식별
비즈니스 요구사항을 분석해서 뽑아낸 핵심 엔티티는 다음과 같다:
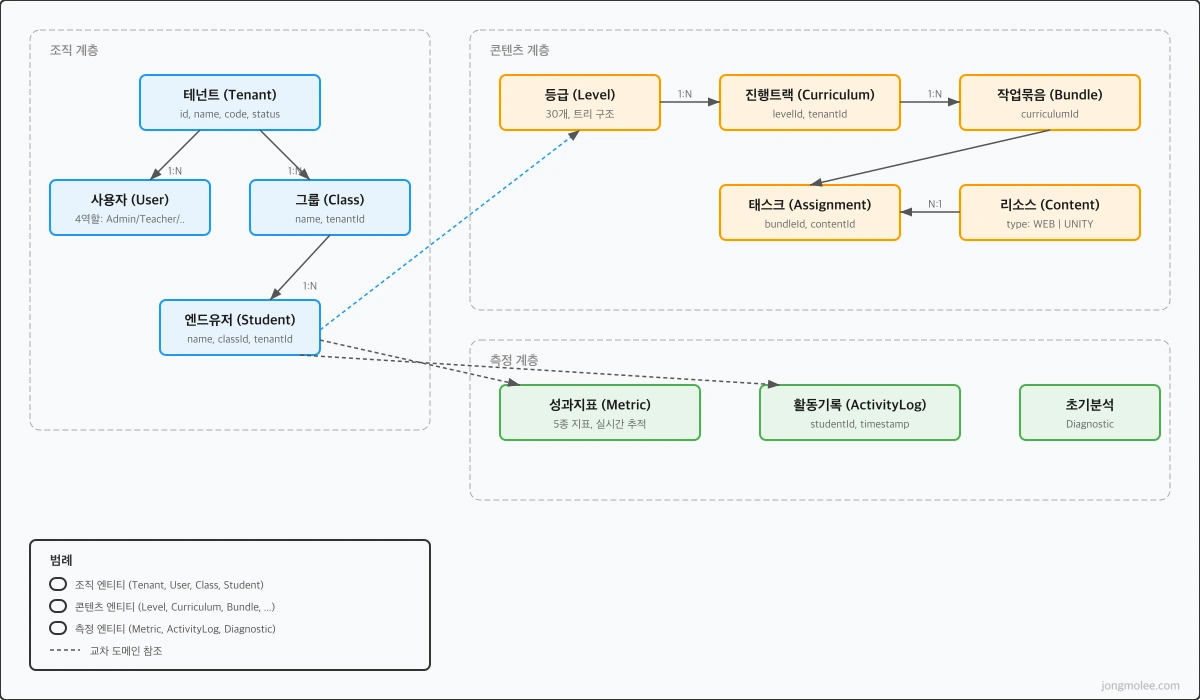
조직 계층
Tenant (테넌트)
└─ Class (그룹)
└─ Member (엔드유저)콘텐츠 계층
Level (등급) ─── 30개, 트리 구조
└─ Curriculum (진행 트랙)
└─ Bundle (작업 묶음)
└─ Assignment (태스크)
└─ Content (리소스)측정 계층
Metric (성과 지표) ─── 5종 실시간 추적
DiagnosticAttempt (초기 분석 시도)
ActivityLog (활동 기록)처음에 이 구조를 잡는 데만 이틀이 걸렸다. 특히 등급(Level)과 진행 트랙(Curriculum)의 관계가 가장 어려웠다.
등급 시스템의 복잡성
등급이 30개라는 건 단순히 1~30 숫자가 아니었다. 등급끼리 트리 구조로 연결되어 있었다. 스킬 트리를 생각하면 된다.
L1 ─┬─ L2 ─── L3
└─ L4 ─┬─ L5
└─ L6 ─── L7한 등급을 마스터하면 다음 등급으로 올라가는데, 분기점이 있다. L1에서 L2로 갈 수도 있고 L4로 갈 수도 있다. 이게 “멀티트랙”이다.
이걸 테이블로 표현하려면:
model Level {
id Int @id @default(autoincrement())
name String
order Int // 표시 순서
parentId Int? // 상위 등급 (트리 구조)
parent Level? @relation("LevelTree", fields: [parentId], references: [id])
children Level[] @relation("LevelTree")
tenantId Int
tenant Tenant @relation(fields: [tenantId], references: [id])
}자기 참조(self-referential) 관계다. Prisma에서 @relation에 이름을 붙여서 명시적으로 선언해야 한다. 이거 안 하면 Prisma가 어떤 필드가 부모고 어떤 게 자식인지 구분을 못 한다.
🔗 엔티티 관계 설계 — FK 지옥의 시작
엔티티를 식별하는 건 반이고, 진짜 어려운 건 관계(FK) 설계다.
테넌트 격리 — 모든 곳에 tenantId
B2B SaaS에서 가장 중요한 건 데이터 격리다. 테넌트 A의 데이터가 테넌트 B에게 보이면 안 된다. 가장 단순한 방법은 모든 테이블에 tenantId를 넣는 것:
model Member {
id Int @id @default(autoincrement())
name String
tenantId Int
tenant Tenant @relation(fields: [tenantId], references: [id])
classId Int
class Class @relation(fields: [classId], references: [id])
}
model Class {
id Int @id @default(autoincrement())
name String
tenantId Int
tenant Tenant @relation(fields: [tenantId], references: [id])
members Member[]
}이렇게 하면 모든 쿼리에 WHERE tenantId = ?를 붙여야 한다. 빠뜨리면 데이터가 섞인다.
나중에 NestJS Guard로 이걸 강제하게 되는데, 그건 4편(권한 매트릭스)에서 다룰 예정.
작업 묶음(Bundle) → 태스크(Assignment) → 리소스(Content) 3단 구조
이 서비스의 핵심 도메인은 콘텐츠 소비 흐름이었다:
- 운영자가 **작업 묶음(Bundle)**을 만든다
- 묶음 안에 **태스크(Assignment)**를 배치한다
- 각 태스크는 특정 **리소스(Content)**를 참조한다
- 엔드유저가 태스크를 수행하면 성과 지표가 갱신된다
model Bundle {
id Int @id @default(autoincrement())
name String
curriculumId Int
curriculum Curriculum @relation(fields: [curriculumId], references: [id])
assignments Assignment[]
tenantId Int
tenant Tenant @relation(fields: [tenantId], references: [id])
}
model Assignment {
id Int @id @default(autoincrement())
order Int // 묶음 내 순서
bundleId Int
bundle Bundle @relation(fields: [bundleId], references: [id])
contentId Int
content Content @relation(fields: [contentId], references: [id])
}
model Content {
id Int @id @default(autoincrement())
title String
type ContentType // WEB | UNITY
category Category // ASSIGNMENT | PLAYGROUND
assignments Assignment[]
}여기서 고민이 생겼다. Assignment와 Content는 1:1인가 N:1인가?
처음에는 1:1로 설계했다. 태스크 하나에 리소스 하나. 깔끔하다.
그런데 클라이언트가 “같은 리소스를 다른 묶음에서도 써야 한다”고 했다. 그러면 N:1이다. 하나의 Content를 여러 Assignment가 참조할 수 있다.
이 결정 하나가 나중에 “리소스 후보 선택 알고리즘”을 만들 때 큰 영향을 미쳤다. v2.1.5까지 3차례 최적화를 하게 된 원인 중 하나.
성과 지표(Metric) — 5종 실시간 추적
엔드유저의 활동 결과를 5개 지표로 추적해야 했다:
model MetricCumulative {
id Int @id @default(autoincrement())
memberId Int
member Member @relation(fields: [memberId], references: [id])
metric1 Float @default(0) // 지표 A
metric2 Float @default(0) // 지표 B
metric3 Float @default(0) // 지표 C
metric4 Float @default(0) // 지표 D
metric5 Float @default(0) // 지표 E
updatedAt DateTime @updatedAt
}처음에는 각 지표를 별도 테이블로 분리할까 했다. 정규화 관점에서는 그게 맞는데, 실시간으로 5개 지표를 동시에 읽어야 하는 상황에서 JOIN 5개는 너무 무겁다.
결국 비정규화해서 한 테이블에 5개 컬럼을 넣었다. 이건 나중에 N+1 쿼리 문제와 맞물려서 성능 최적화 편에서 다시 다루게 된다.
📐 유즈케이스 정의 — API가 될 것들
엔티티 관계를 잡은 다음에는 유즈케이스를 정의했다. “이 시스템에서 누가 뭘 하는가?”
역할별 유즈케이스
관리자(Admin) — 시스템 전체를 관리한다:
- 테넌트 CRUD
- 전체 엔드유저 조회
- 시스템 설정 변경
- 글로벌 콘텐츠 관리
운영자(Operator) — 테넌트 내부를 관리한다:
- 그룹(Class) 관리
- 엔드유저 등록/수정/이동
- 작업 묶음 생성/편집
- 진행 트랙 설정
- 성과 리포트 조회
엔드유저(Member) — 태스크를 수행한다:
- 배정된 태스크 조회
- 태스크 수행 (리소스 소비)
- 내 성과 지표 확인
- 리워드/포인트 확인
외부 뷰어(Parent) — 특정 엔드유저의 현황을 본다:
- 성과 리포트 (읽기 전용)
- 활동 기록 조회
- QR 코드로 접근 (토큰 기반 인증)
이 유즈케이스가 나중에 **시나리오 코드(SC-A01A20, SC-B01B29)**로 구체화되고, 각 시나리오가 API 엔드포인트가 된다.
시나리오 코딩의 힘
SC-A01: 관리자 - 테넌트 목록 조회 → GET /api/v1/admin/tenants
SC-A02: 관리자 - 테넌트 상세 조회 → GET /api/v1/admin/tenants/:id
SC-A03: 관리자 - 테넌트 생성 → POST /api/v1/admin/tenants
SC-A04: 관리자 - 테넌트 수정 → PATCH /api/v1/admin/tenants/:id
SC-A05: 관리자 - 테넌트 상태 변경 → PATCH /api/v1/admin/tenants/:id/status
...유즈케이스를 시나리오 코드로 부여하면 좋은 점:
- 추적이 된다 — “SC-A01 구현됐어?” → Yes/No
- 커밋에 태깅이 된다 —
feat: SC-A01~A05 테넌트 관리 API - QA가 쉽다 — “SC-B15 시나리오 테스트 통과?”
나중에 Admin Portal 20개 시나리오를 구현할 때, 이 코딩 체계 덕에 하루에 5~6개 시나리오를 소화할 수 있었다.
🏗️ ERD 초안 — 관계도 그려보기
엔티티와 유즈케이스를 정리하고 나면, 관계도(ERD)를 그려야 한다. 초기 설계에서 도출된 핵심 테이블:
┌─────────────────────────────────────────────────┐
│ Tenant │
│ id, name, code, status │
├─────────────────────────────────────────────────┤
│ │ │ │
│ ▼ ▼ │
│ ┌──────┐ ┌──────────┐ │
│ │ User │ │ Class │ │
│ │ role │ │ │ │
│ └──────┘ └──────────┘ │
│ │ │
│ ▼ │
│ ┌──────────┐ │
│ │ Member │ │
│ └──────────┘ │
│ │ │ │
│ ▼ ▼ │
│ ┌──────────┐ ┌───────────────┐ │
│ │ Activity │ │ MetricCumul. │ │
│ │ Log │ │ (5 metrics) │ │
│ └──────────┘ └───────────────┘ │
└─────────────────────────────────────────────────┘
┌─────────────────────────────────────────────────┐
│ 콘텐츠/활동 계층 │
│ │
│ Level (30개, 트리) │
│ └─ Curriculum (진행 트랙) │
│ └─ Bundle (작업 묶음) │
│ └─ Assignment (태스크) │
│ └─ Content (리소스, N:1) │
│ │
│ DiagnosticAttempt (초기 분석) │
│ └─ Member │
│ └─ Level │
└─────────────────────────────────────────────────┘총 15개 테이블이 초안에 나왔다. 이게 나중에 30개로 늘어난다. v2.0에서는 더 늘어난다.
처음부터 30개를 설계하려고 했으면 끝나지 않았을 거다. 핵심 엔티티 15개를 먼저 잡고, 필요할 때 추가하는 전략이 1인 개발에서는 맞았다.
⚡ 첫 번째 교훈들

1. “이거 어디 속하지?” 판별법
엔티티를 분류할 때 헷갈리면 이 질문을 한다:
“이 데이터가 없으면 시스템이 돌아가는가?”
- Tenant 없으면? → 시스템 자체가 안 돌아감 → 핵심 엔티티
- ActivityLog 없으면? → 기능은 돌아가지만 추적이 안 됨 → 부가 엔티티
- MetricCumulative 없으면? → 등급 조정이 안 됨 → 핵심 엔티티
핵심 엔티티는 먼저 설계하고, 부가 엔티티는 필요할 때 추가한다.
2. 1:N보다 N:M이 무서운 이유
처음에 Level과 Content의 관계를 1:N으로 잡았다. “한 등급에 여러 리소스가 있다.”
그런데 “한 리소스가 여러 등급에서 사용될 수 있다”는 요구사항이 추가되면서 N:M이 됐다.
// 1:N일 때 — 단순
model Content {
levelId Int
level Level @relation(fields: [levelId], references: [id])
}
// N:M일 때 — 중간 테이블 필요
model ContentLevel {
contentId Int
content Content @relation(fields: [contentId], references: [id])
levelId Int
level Level @relation(fields: [levelId], references: [id])
@@id([contentId, levelId])
}N:M 관계가 추가되면 쿼리가 복잡해지고, JOIN이 하나 더 늘어나고, 중간 테이블의 데이터 정합성도 관리해야 한다. 그래서 도메인 모델링 단계에서 관계의 카디널리티를 정확히 파악하는 게 중요하다.
3. 비즈니스 용어 통일
이건 사소해 보이지만 엄청 중요하다. 클라이언트가 “고객사”이라고 할 때 코드에서는 tenant인지 organization인지 tenant인지. “유저”이 user인지 member인지 learner인지.
마스터 문서에 용어 사전(Glossary) 을 만들었다:
| 비즈니스 용어 | 코드 용어 | 설명 |
|---|---|---|
| 고객사 | Tenant | 서비스를 사용하는 조직 단위 |
| 그룹 | Class | 테넌트 내 엔드유저 묶음 |
| 엔드유저 | Member | 태스크를 수행하는 사람 |
| 운영자 | Operator | 테넌트를 관리하는 사람 |
| 등급 | Level | 스킬 레벨 (1~30) |
| 작업 묶음 | Bundle | 태스크의 논리적 그룹 |
| 태스크 | Assignment | 엔드유저가 수행하는 개별 작업 |
| 리소스 | Content | 태스크에 연결된 콘텐츠 |
이 용어 사전이 있으니까 문서를 읽을 때도, 코드를 쓸 때도, 클라이언트와 대화할 때도 같은 언어를 쓸 수 있었다.
🤔 설계 vs 코딩 — 9일은 길었나?
솔직히 3일째부터 “이제 코딩하고 싶다”는 충동이 올라왔다. 문서만 계속 쓰니까 진도가 안 나가는 느낌이었다.
그런데 9일째에 마스터 문서를 다시 읽어보니까, 이게 있으니까 스키마가 바로 나온다는 걸 알았다. 문서에서 엔티티를 뽑고, 관계를 확인하고, Prisma 스키마로 옮기면 된다.
실제로 다음 편(#3)에서 30개 테이블 스키마를 이틀 만에 완성한다. 도메인 모델링 없이 바로 스키마를 쓰려고 했으면 일주일은 걸렸을 거다.
도메인 모델링 타임라인
| 일차 | 작업 | 산출물 |
|---|---|---|
| Day 1~2 | 클라이언트 미팅, 요구사항 정리 | 마스터.md (709줄) |
| Day 3~4 | 비즈니스 규칙 질문 정리 | 필요_정의사항_명확화.md (1,029줄) |
| Day 5~6 | 엔티티 식별, 관계 설계 | erd.md (393줄) |
| Day 7~8 | 유즈케이스 정의, MVP 범위 | MVP_EPR_정의.md (132줄) |
| Day 9 | 우선순위 정의, 마일스톤 설정 | 우선순위정의.md (223줄) |
총 2,486줄의 설계 문서. 이게 향후 4개월의 나침반이 됐다.
💡 도메인 모델링 체크리스트
이 경험을 정리하면:
- 마스터 문서를 먼저 쓴다 — 코드 전에 도메인을 이해한다
- 결정해야 할 것을 리스트업한다 — 코딩하면서 결정하면 뒤엎게 된다
- 핵심 엔티티부터 식별한다 — “없으면 시스템이 안 돌아가는 것”
- 관계의 카디널리티를 정확히 파악한다 — 1:N이 N:M으로 바뀌면 구조가 흔들린다
- 용어를 통일한다 — 비즈니스 용어와 코드 용어의 매핑 테이블을 만든다
- ERD를 그린다 — 머릿속 모델을 시각화하면 빠진 관계가 보인다
📊 오늘의 숫자
| 항목 | 값 |
|---|---|
| 코드 커밋 | 0개 (문서만 씀) |
| 설계 문서 | 2,486줄 (5개 파일) |
| 핵심 엔티티 | 15개 (초안) |
| 식별된 관계 | 23개 FK |
| 설계 기간 | 9일 |
| 비즈니스 결정사항 | 47개 |
🔜 다음에 할 것
- Prisma 스키마 설계 — 30개 테이블의 탄생기
- self-referential 관계 삽질
- enum vs 도메인 타입 선택
- 마이그레이션 첫 실행
📚 NestJS + Refine 풀스택 트러블슈팅 시리즈 (63편)
- 1. 왜 NestJS + Prisma를 선택했나 — B2B SaaS 백엔드 기술 선택기
- 2. 도메인 모델링 첫날 — B2B SaaS의 핵심 엔티티 정의하기
- 3. 27개 테이블의 탄생 — Prisma 스키마 설계기
- 4. 권한 매트릭스 — Admin/운영자/사용자 3역할 설계
- 5. BigInt PK에서 Int PK로 — 첫 번째 스키마 리팩토링
- 6. Seed 데이터의 함정 — FK 삭제 순서 삽질기
- 7. DDD를 도입하기로 했다 — Repository/Domain/Application 3계층
- 8. 인터페이스 구현체로 바꾸는 날 — NestJS DI와 TypeScript의 간극
- 9. 단위 테스트 인프라 구축 — Jest 설정부터 Mock까지
- 10. E2E 테스트와 Cloud SQL의 고난 — 4/8 passing에서 8/8까지
- 11. REST API 첫 구현 — 6개 Controller, 21개 엔드포인트 완성
- 12. v1.0 완성, 그리고 갈아엎기로 결심한 날
- 13. 번들 구조를 통째로 바꿔야 했던 이유
- 14. Phase 1 문서 정비 — Use Case를 번들 기반으로 다시 쓰다
- 15. Phase 2 스키마 마이그레이션 — 데이터 안 날리고 구조 바꾸기
- 16. Phase 3-1·3-2 — Repository와 Domain 서비스로 36개 빌드 에러 잡기
- 17. Phase 3-3·3-4·3-5 — Application부터 Module까지, v2.0 마이그레이션 닫는 날
- 18. 코드를 박은 다음 날 — 4,658줄 DDD 문서를 24분 사이에 다시 쓴 하루
- 19. v2.1 Domain Layer — 도메인 서비스 1,682줄을 한 커밋에 박은 날의 설계 철학
- 20. v3.0 Application Layer 재작성 — 도메인 서비스 위에 얇은 막을 한 Phase에 박은 날
- 21. 갈아엎고 80일 — v2.0 마이그레이션 8편 메타 회고
- 22. 1인 다역으로 5일 만에 90% — Admin Portal MVP를 끌어올린 토글 한 줄
- 23. Mock에선 되던 게 REST에선 안 됐다 — 응답 포맷 한 칸 차이가 만든 하루
- 24. CORS는 됐다 — PATCH만 빼고. allowedHeaders 한 줄과 Vite 프록시의 소문자 메서드
- 25. 멀티테넌트 누수 — tenantId 3계층 강제
- 26. Prisma 정책 싱글톤 — zod superRefine 임계값 가드
- 27. 멀티테넌트 쓰기 가드 — body.tenantId 차단과 집계 일관성
- 28. 두 번째 점검은 합류 지점이었다 — Admin Portal 2차에서 한 사이클에 잡힌 FE-BE 연동 버그 11건
- 29. Prisma 그래프 스키마 — 선형 레벨을 DAG로 옮긴 4가지 결정
- 30. 교육과정 구조 리팩토링 — 3필드 분리와 폴백 결정기
- 31. 배치고사 MVP — 자동 레벨 배치를 걷어내고 5지표 측정만 남기다
- 32. JWT Guard 적용 — request.user undefined부터 jwt malformed까지
- 33. 디버깅용 운영 API 7개 — Unity 만료 테스트 30분 대기를 0초로
- 34. NestJS Swagger 일괄 적용 — 35개 컨트롤러 + DTO 22개
- 35. Unity ↔ 웹 PostMessage 브릿지 설계기
- 36. Vuplex 브릿지 초기화 타이밍 — 첫 메시지가 증발한 이유
- 37. 콘텐츠 브릿지 10종 통합 완료 — 같은 규격으로 묶기
- 38. 지표 누계 시스템 — TOP5 순위를 INSERT 전용 스냅샷으로 굳히기
- 39. 킥오프 배치 첫 구현 — 매시 전체 EXPIRED 사고와 Winston 도입
- 40. 혼자 여러 역할로 QA 1차 — 브랜치 미동기화와 잔존 토큰의 함정
- 41. 타이머가 NaN:NaN으로 떴다 — Bundle API 응답 누락 필드와 비어 있는 콘텐츠 후보
- 42. 1인 개발 QA 5라운드 — 타이머·시드·스키마로 옮긴 버그들
- 43. Unity Lobby + 배치고사 씬 통합 — 두 클라이언트가 같은 회원을 보는 첫 빌드
- 44. 배치고사 MVP 후속 — 명세를 코드로 옮기고 레거시 571줄을 일괄 삭제하다
- 45. Problem 종속 끊기 — 1,891개 마이그레이션과 단위 테스트 38건
- 46. NestJS 권한 가드 — 목록은 막고 상세는 뚫린 날
- 47. 콘텐츠 후보 선택 3차 최적화 — 단일 쿼리로 옮기기
- 48. 재화 시스템 첫 머지 — 코인 지갑과 거래 원장(Wallet API)
- 49. 회원 레포트 5탭 API 설계 — 인사이트 3파트 구조
- 50. 보호자 외부 뷰어 대시보드 — 모바일 앱·초대 토큰 회원가입
- 51. 외부 뷰어 리포트 v1→v2 토큰 전환 — 가장 길었던 하루
- 52. 외부 뷰어 리포트 인사이트 — 활동 데이터를 자연어로 바꾸기
- 53. Framer Motion whileInView — 일부 카드만 안 뜨던 날
- 54. 외부 뷰어 리포트 4탭 N+1 — 14초 응답을 2초로
- 55. Cloud SQL 리전 트랩 — US→Taiwan 71% 트러블슈팅
- 56. QR 배치고사 + Firebase Hosting 멀티 사이트 배포
- 57. 1,974줄 풀 백업 — 1인 개발에서 상태 관리하는 법
- 58. 주간 출석 KST 타임존 — 월요일이 사라진 트러블슈팅
- 59. 연락처 포맷 통일 — 저장은 숫자만, 표시는 하이픈
- 60. react-hook-form + Zod 폼 표준 정착기
- 61. Soft Delete 구현 — deletedAt 한 컬럼이 닿은 27곳의 설계
- 62. 교육과정 자동 승급의 늪 — 도메인 버그 3 건 트러블슈팅
- 63. 교육과정 도메인 BE 완성과 같은 날 핫픽스 7 건 — NestJS @Cron 2 중 실행 묶음