v1.0 완성, 그리고 갈아엎기로 결심한 날
📚 NestJS + Refine 풀스택 트러블슈팅 시리즈 (63편)
358개 테스트, 30개 테이블, 6개 Controller까지 완성한 v1.0. 기획 검토 한 번에 핵심 구조가 통째로 바뀌었다. Block에서 Bundle로, 갈아엎기로 결심하기까지의 기록.
💡 Tip. 바쁜 현대인들을 위한 본문 요약
- 358개 테스트, 30개 테이블, 6개 Controller — v1.0이 “완성”되었다. E2E 테스트까지 통과한 상태
- 기획자와 검토 미팅 한 번에 핵심 도메인 구조가 통째로 바뀌었다. Block(가변 개수, 2타입) → Bundle(5개 고정, 레벨링 모듈 추가)
- 패치로 때울 수 있는 수준이 아니었다. Prisma 스키마 2개 테이블 삭제 + 2개 신규 생성, Use Case 문서 전면 재작성
- DDD 3계층 구조 덕분에 “갈아엎기”가 가능했다. 고위험 영역만 재작성하고, 안정 영역(24개 테이블)은 보존하는 하이브리드 접근법
- v1.0을 아카이빙하고 v2.0 마이그레이션 로드맵을 세웠다. 5단계, 예상 2~3주
🏁 발단 — v1.0이 “완성”된 순간
이전 편에서 REST API Controller 6개를 완성하고, 전체 358개 테스트가 통과하는 상태까지 왔다. 그리고 E2E 테스트도 추가해서 실제 Cloud SQL 위에서 돌아가는 것까지 확인했다.
숫자로 보면 꽤 그럴듯했다.
| 항목 | 수치 |
|---|---|
| Prisma 테이블 | 30개 |
| Application Service | 6개 |
| REST Controller | 6개 |
| 단위 테스트 | 257개 |
| Controller 테스트 | 27개 |
| 통합 테스트 | 101개 |
| E2E 테스트 | 8개+ |
| 합계 | 358개+ |
“이 정도면 MVP 나가도 되겠다”고 생각했다. 기획자에게 현재 상태를 공유하고 검토 미팅을 잡았다. 지금까지 만든 것이 기획 의도와 맞는지 확인하려고.
📌 핵심: 코드가 “완성”되었다고 해서 프로덕트가 완성된 건 아니다. 기획 검토 없이 코드만 열심히 쌓으면, 나중에 더 큰 대가를 치르게 된다.
🔍 E2E 테스트에서 이미 보였던 징조
사실 기획 검토 전에도 불안한 신호는 있었다. E2E 테스트를 Assignment(태스크) 관련 Use Case로 확장하는 과정에서, 스키마 필드명이 자꾸 안 맞는 문제가 터졌다.
wip: Assignment E2E 테스트 스키마 필드명 수정 (2/8 passing)8개 테스트 중 6개가 실패. 원인을 파보니 이런 불일치들이 나왔다.
| DTO 필드 | 실제 스키마 필드 | 문제 |
|---|---|---|
runtime | runtimeMinutes | 단위 누락 |
assignedAt | scheduledAt | 의미 불일치 |
completedAt | submittedAt | 관점 차이 |
contentId | selectedContentId | 네이밍 불일치 |
단위 테스트에서는 Mock을 써서 이런 불일치가 드러나지 않았다. 실제 DB를 치는 E2E 테스트에서야 비로소 스키마와 코드 사이의 간극이 보였다.
🔍 단서: 단위 테스트 100% 통과가 “다 됐다”는 의미는 아니다. Mock은 “이렇게 동작할 것이다”라는 가정이지 증명이 아니다. E2E 테스트가 그 가정을 검증한다.
하지만 이건 필드명 수정으로 해결할 수 있는 수준이었다. 진짜 문제는 다른 곳에 있었다.
🔥 기획 검토 — “블록이 아니라 번들입니다”
기획자에게 현재 구현 상태를 공유했더니, 돌아온 피드백이 이랬다.
“중요 로직들의 핵심 변화 사항이 생겼어요. 기존 문서에 반영하면 전파 사항이 많아서 디테일을 놓칠 우려가 있습니다.”
핵심만 추리면 이렇다.
1. Block → Bundle, 이름만 바뀐 게 아니다
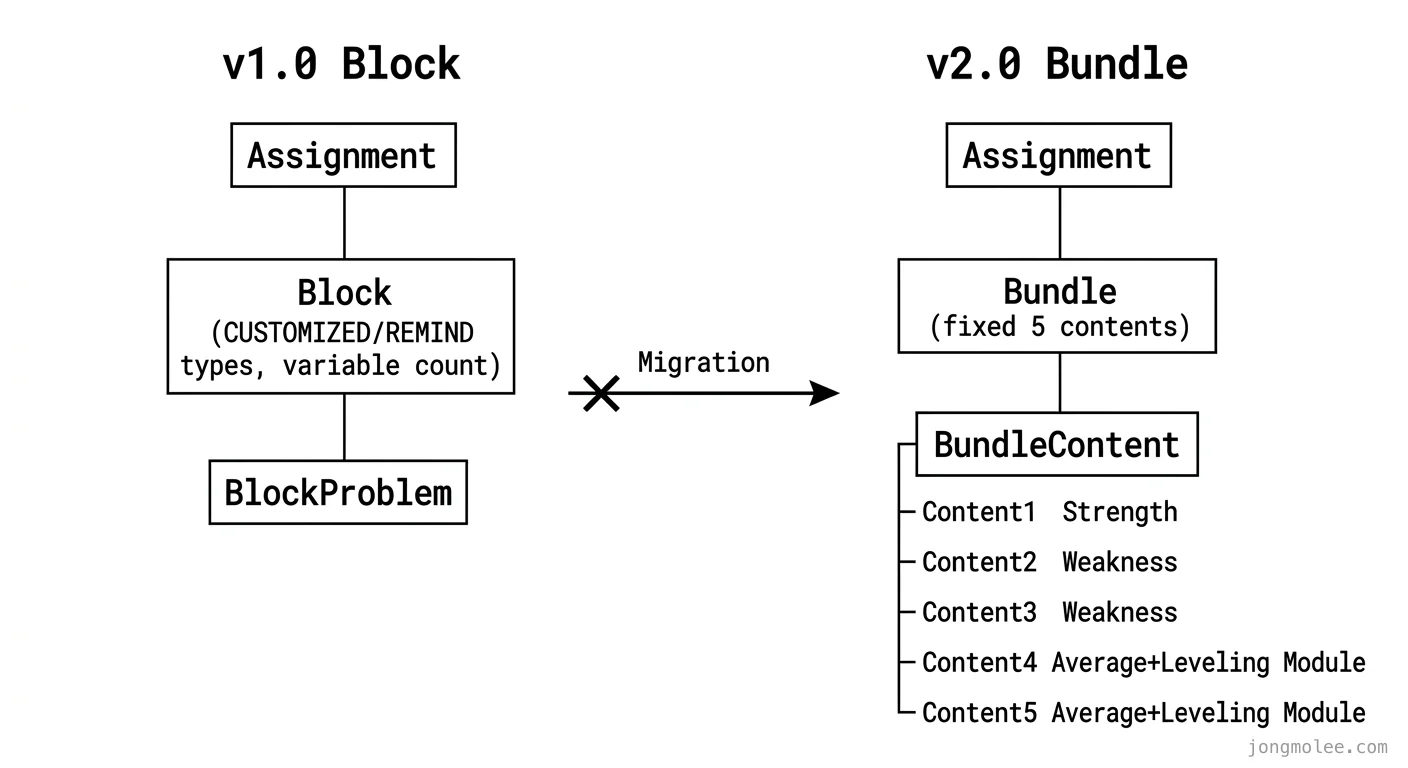
v1.0의 Block은 단순했다. 태스크(Assignment) 안에 Block이 가변 개수로 들어가고, 각 Block은 CUSTOMIZED(맞춤형)나 REMIND(복습) 중 하나였다.
// v1.0 Block — 가변 개수, 2가지 타입
model Block {
id BigInt @id @default(autoincrement())
assignmentId BigInt
seq Int
blockType BlockType // CUSTOMIZED | REMIND
targetLevelId Int
targetMetricCode MetricCode?
selectedContentId Int
status BlockStatus
accuracyPct Float?
...
}v2.0의 Bundle은 완전히 다른 구조였다. 5개 콘텐츠가 고정으로 들어가고, 각 콘텐츠는 역할이 정해져 있다.
| 순번 | 역할 | 지표 선택 기준 |
|---|---|---|
| 콘텐츠 1 | 강점 강화 | 가장 높은 지표 |
| 콘텐츠 2~3 | 약점 보강 | 가장 낮은 지표 |
| 콘텐츠 4~5 | 평균 + 레벨 조정 | 2~4순위 랜덤 + 레벨링 모듈 결과 |
2. 레벨링 모듈이라는 새 개념
v1.0에는 없던 메커니즘이 추가됐다. 콘텐츠 13번의 정답률을 기반으로, 콘텐츠 45번의 난이도를 실시간으로 조정하는 로직이다.
콘텐츠 1~3 클리어
→ 정답률 평균 계산
→ 90%+ : 레벨 유지
→ 40~89% : 1~(현재레벨-1) 중 랜덤
→ 0~39% : 연관 하위 레벨로 강제 이동
→ 조정된 난이도로 콘텐츠 4 클리어
→ 콘텐츠 4 단독 정답률로 콘텐츠 5 레벨 재조정이건 기존 Block 모델에 필드 몇 개 추가해서 해결할 수 있는 수준이 아니었다. Block과 BlockProblem 두 테이블을 통째로 들어내고, Bundle과 BundleContent 새 테이블을 만들어야 했다.
3. 그 외 변경사항
- 자유 활동 → 신기록 도전으로 개념 자체가 변경
- 번들 제한 시간 30분 도입 (반별 설정 가능)
- 미완료 번들의 지표 미반영 규칙 추가
- 콘텐츠 재시도 조건 변경
⚠️ 주의: “이름만 바꾸면 되는 거 아니야?”라고 생각할 수 있다. 아니다. 도메인 모델이 바뀌면 그 위에 쌓인 모든 계층이 흔들린다. Repository, Domain Service, Application Service, Controller, 테스트 — 전부 영향 범위 안에 있다.
🤔 결정 — 패치할 것인가, 갈아엎을 것인가
두 가지 선택지가 있었다.
선택지 1: 기존 코드 위에 패치
- Block 테이블에 컬럼 추가
- BlockType enum 확장
- 기존 테스트 수정
- 예상 시간: 1~2주
선택지 2: 핵심 영역 재작성 (하이브리드)
- Block, BlockProblem 삭제 → Bundle, BundleContent 신규
- 관련 Use Case 문서 재작성
- Repository, Domain, Application 계층 재작성
- 안정 영역(User, Level 등 24개 테이블)은 보존
- 예상 시간: 2~3주
선택지 2를 골랐다. 이유는 명확했다.
패치하면 당장은 빠르다. 하지만 Block 모델 위에 Bundle의 의미를 억지로 올리는 꼴이 된다. blockType이라는 컬럼에 STRENGTH, WEAKNESS, AVERAGE 같은 값이 들어가게 된다. 나중에 코드를 보는 사람(미래의 나 포함)은 “왜 Block인데 Bundle처럼 동작하지?”라는 혼란에 빠질 거다.
📌 핵심: 도메인 모델과 코드의 언어가 일치하지 않으면, 시간이 지날수록 인지 부하가 쌓인다. DDD에서 “유비쿼터스 언어”를 강조하는 이유가 이거다. 기획에서 “번들”이라고 부르는데 코드에서
Block이면, 매번 머릿속에서 번역해야 한다.
📊 영향 범위 분석
갈아엎기로 결심한 뒤, 가장 먼저 한 일은 영향 범위를 정량화하는 것이었다.
| 영역 | 재작성 | 수정 | 보존 |
|---|---|---|---|
| Prisma 테이블 | 2개 (Block, BlockProblem → Bundle, BundleContent) | 3개 (Assignment, ContentAttempt 등) | 24개 |
| NestJS 모듈 | 2개 (Assignment, FreeLearning) | 3개 (LevelAdjustment 등) | 13개 |
| Use Case 문서 | 2개 | 2개 | 2개 |
| 테스트 | ~40% | ~20% | ~40% |
30개 테이블 중 24개가 그대로다. 80%는 건드리지 않아도 된다. DDD로 계층을 잘 분리해놨기 때문에 가능한 숫자다. Assignment 관련 Bounded Context만 들어내면 나머지는 영향을 받지 않는다.
🔍 단서: 이 영향 범위 분석이 “갈아엎기” 결정의 근거가 됐다. 만약 전체 테이블의 50% 이상이 영향을 받았다면, 처음부터 새 프로젝트를 만드는 게 나았을 것이다. 80%를 보존할 수 있으니까 마이그레이션이 합리적인 선택이었다.
🗺️ 5-Phase 마이그레이션 로드맵
하이브리드 접근법으로 5단계 로드맵을 세웠다.
| Phase | 작업 | 예상 기간 | 접근법 |
|---|---|---|---|
| 1 | 문서 정비 (Use Case, DDD 문서) | 1~2일 | 재작성 |
| 2 | Prisma Schema 마이그레이션 | 2~3일 | 재작성 |
| 3 | NestJS 모듈 (Repository → Domain → Application → Controller → Module) | 3~5일 | 재작성+수정 |
| 4 | 테스트 업데이트 | 2~3일 | 재작성+수정 |
| 5 | 통합 검증 | 1~2일 | 검증 |
총 예상 기간은 915일(23주). 현실적인 숫자였다.
Phase 순서가 중요하다. 문서를 먼저 정비하는 이유가 있다. 코드를 바꾸기 전에 “뭘 바꿀 건지”를 먼저 명확히 해야 한다. Use Case 문서가 SSoT(Single Source of Truth)이고, 코드는 그 문서의 구현체다.
Phase 1: 문서 = "무엇을 만들 것인가" 재정의
Phase 2: 스키마 = "데이터를 어떻게 저장할 것인가" 재정의
Phase 3: 코드 = "어떻게 동작할 것인가" 재구현
Phase 4: 테스트 = "제대로 동작하는가" 재검증
Phase 5: 통합 = "전체가 맞물리는가" 최종 확인📌 핵심: 마이그레이션은 “코드부터 수정”이 아니라 “문서부터 수정”이다. 문서 없이 코드를 먼저 바꾸면, 중간에 방향을 잃었을 때 돌아갈 곳이 없다.
🗃️ v1.0 아카이빙
마지막으로 한 일은 v1.0 문서를 아카이빙하는 것이었다.
docs/
├── 00_프로젝트_마스터_v2.0.md ← 신규 (1,013줄)
├── V2_MIGRATION_ROADMAP.md ← 신규 (441줄)
├── 기획자_검토내용.txt ← 원본 피드백
├── _archived/
│ └── 00_프로젝트_마스터_v1.1.md ← 아카이빙
└── ...v1.0 마스터 문서를 삭제하지 않고 _archived/로 옮겼다. 왜 v2.0이 필요했는지를 나중에 돌아볼 수 있어야 하니까. PRD(Product Requirements Document)도 v1.1을 아카이빙하고 v2.0을 새로 작성했다.
그리고 CLAUDE.md(AI 지식 전승 문서)를 만들었다. 이 프로젝트에서 CLAUDE.md가 처음 등장한 순간이다. v2.0으로 전환하면서 프로젝트의 핵심 컨텍스트를 한곳에 정리할 필요가 생겼기 때문이다.
⚠️ 주의: 아카이빙은 “이 코드는 쓸모없다”가 아니다. “이 코드가 왜 바뀌었는지”를 기록하는 행위다. 1년 뒤의 나에게 보내는 맥락이다.
📋 정리 — 핵심 요약
358개 테스트가 통과하는 “완성된” v1.0을 만들고, 같은 날 그걸 갈아엎기로 결심했다. 기획 검토 한 번이 한 달간의 코드보다 무거웠다.
| 시점 | 상태 |
|---|---|
| 오전 | E2E 테스트 추가, 358개+ 테스트 통과 |
| 오후 | 기획자 검토 — Block → Bundle 핵심 구조 변경 확인 |
| 저녁 | v2.0 마스터 문서(1,013줄) + 마이그레이션 로드맵(441줄) 작성 |
| 상황 | 안티패턴 | 권장 패턴 |
|---|---|---|
| 도메인 모델 변경 | ❌ 기존 테이블에 컬럼 추가로 떼움 | ✅ 핵심 영역 재작성 + 안정 영역 보존 |
| 네이밍 불일치 | ❌ 코드는 Block, 기획은 Bundle | ✅ 유비쿼터스 언어 일치 (코드 = 기획 용어) |
| 마이그레이션 시작 | ❌ 코드부터 수정 | ✅ 문서(SSoT) → 스키마 → 코드 → 테스트 순서 |
| 과거 코드 | ❌ 삭제 | ✅ _archived/에 보존 (변경 사유 추적) |
| 영향 범위 | ❌ 감으로 판단 | ✅ 테이블/모듈/테스트 단위로 정량화 |
📌 핵심: 코드를 갈아엎는 건 실패가 아니다. 기획이 바뀌었으니 코드도 바뀌는 게 정상이다. 진짜 실패는 기획이 바뀌었는데 코드를 억지로 유지하는 것이다. DDD의 계층 분리 덕분에 80%를 보존하면서 핵심만 교체할 수 있었다.
다음 편에서는 Bundle 구조를 통째로 바꿔야 했던 이유와 5-Phase 마이그레이션의 첫 삽을 뜨는 이야기를 다룬다.
📚 NestJS + Refine 풀스택 트러블슈팅 시리즈 (63편)
- 1. 왜 NestJS + Prisma를 선택했나 — B2B SaaS 백엔드 기술 선택기
- 2. 도메인 모델링 첫날 — B2B SaaS의 핵심 엔티티 정의하기
- 3. 27개 테이블의 탄생 — Prisma 스키마 설계기
- 4. 권한 매트릭스 — Admin/운영자/사용자 3역할 설계
- 5. BigInt PK에서 Int PK로 — 첫 번째 스키마 리팩토링
- 6. Seed 데이터의 함정 — FK 삭제 순서 삽질기
- 7. DDD를 도입하기로 했다 — Repository/Domain/Application 3계층
- 8. 인터페이스 구현체로 바꾸는 날 — NestJS DI와 TypeScript의 간극
- 9. 단위 테스트 인프라 구축 — Jest 설정부터 Mock까지
- 10. E2E 테스트와 Cloud SQL의 고난 — 4/8 passing에서 8/8까지
- 11. REST API 첫 구현 — 6개 Controller, 21개 엔드포인트 완성
- 12. v1.0 완성, 그리고 갈아엎기로 결심한 날
- 13. 번들 구조를 통째로 바꿔야 했던 이유
- 14. Phase 1 문서 정비 — Use Case를 번들 기반으로 다시 쓰다
- 15. Phase 2 스키마 마이그레이션 — 데이터 안 날리고 구조 바꾸기
- 16. Phase 3-1·3-2 — Repository와 Domain 서비스로 36개 빌드 에러 잡기
- 17. Phase 3-3·3-4·3-5 — Application부터 Module까지, v2.0 마이그레이션 닫는 날
- 18. 코드를 박은 다음 날 — 4,658줄 DDD 문서를 24분 사이에 다시 쓴 하루
- 19. v2.1 Domain Layer — 도메인 서비스 1,682줄을 한 커밋에 박은 날의 설계 철학
- 20. v3.0 Application Layer 재작성 — 도메인 서비스 위에 얇은 막을 한 Phase에 박은 날
- 21. 갈아엎고 80일 — v2.0 마이그레이션 8편 메타 회고
- 22. 1인 다역으로 5일 만에 90% — Admin Portal MVP를 끌어올린 토글 한 줄
- 23. Mock에선 되던 게 REST에선 안 됐다 — 응답 포맷 한 칸 차이가 만든 하루
- 24. CORS는 됐다 — PATCH만 빼고. allowedHeaders 한 줄과 Vite 프록시의 소문자 메서드
- 25. 멀티테넌트 누수 — tenantId 3계층 강제
- 26. Prisma 정책 싱글톤 — zod superRefine 임계값 가드
- 27. 멀티테넌트 쓰기 가드 — body.tenantId 차단과 집계 일관성
- 28. 두 번째 점검은 합류 지점이었다 — Admin Portal 2차에서 한 사이클에 잡힌 FE-BE 연동 버그 11건
- 29. Prisma 그래프 스키마 — 선형 레벨을 DAG로 옮긴 4가지 결정
- 30. 교육과정 구조 리팩토링 — 3필드 분리와 폴백 결정기
- 31. 배치고사 MVP — 자동 레벨 배치를 걷어내고 5지표 측정만 남기다
- 32. JWT Guard 적용 — request.user undefined부터 jwt malformed까지
- 33. 디버깅용 운영 API 7개 — Unity 만료 테스트 30분 대기를 0초로
- 34. NestJS Swagger 일괄 적용 — 35개 컨트롤러 + DTO 22개
- 35. Unity ↔ 웹 PostMessage 브릿지 설계기
- 36. Vuplex 브릿지 초기화 타이밍 — 첫 메시지가 증발한 이유
- 37. 콘텐츠 브릿지 10종 통합 완료 — 같은 규격으로 묶기
- 38. 지표 누계 시스템 — TOP5 순위를 INSERT 전용 스냅샷으로 굳히기
- 39. 킥오프 배치 첫 구현 — 매시 전체 EXPIRED 사고와 Winston 도입
- 40. 혼자 여러 역할로 QA 1차 — 브랜치 미동기화와 잔존 토큰의 함정
- 41. 타이머가 NaN:NaN으로 떴다 — Bundle API 응답 누락 필드와 비어 있는 콘텐츠 후보
- 42. 1인 개발 QA 5라운드 — 타이머·시드·스키마로 옮긴 버그들
- 43. Unity Lobby + 배치고사 씬 통합 — 두 클라이언트가 같은 회원을 보는 첫 빌드
- 44. 배치고사 MVP 후속 — 명세를 코드로 옮기고 레거시 571줄을 일괄 삭제하다
- 45. Problem 종속 끊기 — 1,891개 마이그레이션과 단위 테스트 38건
- 46. NestJS 권한 가드 — 목록은 막고 상세는 뚫린 날
- 47. 콘텐츠 후보 선택 3차 최적화 — 단일 쿼리로 옮기기
- 48. 재화 시스템 첫 머지 — 코인 지갑과 거래 원장(Wallet API)
- 49. 회원 레포트 5탭 API 설계 — 인사이트 3파트 구조
- 50. 보호자 외부 뷰어 대시보드 — 모바일 앱·초대 토큰 회원가입
- 51. 외부 뷰어 리포트 v1→v2 토큰 전환 — 가장 길었던 하루
- 52. 외부 뷰어 리포트 인사이트 — 활동 데이터를 자연어로 바꾸기
- 53. Framer Motion whileInView — 일부 카드만 안 뜨던 날
- 54. 외부 뷰어 리포트 4탭 N+1 — 14초 응답을 2초로
- 55. Cloud SQL 리전 트랩 — US→Taiwan 71% 트러블슈팅
- 56. QR 배치고사 + Firebase Hosting 멀티 사이트 배포
- 57. 1,974줄 풀 백업 — 1인 개발에서 상태 관리하는 법
- 58. 주간 출석 KST 타임존 — 월요일이 사라진 트러블슈팅
- 59. 연락처 포맷 통일 — 저장은 숫자만, 표시는 하이픈
- 60. react-hook-form + Zod 폼 표준 정착기
- 61. Soft Delete 구현 — deletedAt 한 컬럼이 닿은 27곳의 설계
- 62. 교육과정 자동 승급의 늪 — 도메인 버그 3 건 트러블슈팅
- 63. 교육과정 도메인 BE 완성과 같은 날 핫픽스 7 건 — NestJS @Cron 2 중 실행 묶음