Cloud SQL 리전 트랩 — US→Taiwan 71% 트러블슈팅
📚 NestJS + Refine 풀스택 트러블슈팅 시리즈 (63편)
외부 뷰어 리포트 4탭 N+1 을 잡아 2.3 초까지 줄였는데 목표 500ms 와의 마지막 1.8 초가 코드 어디에서도 나오지 않았다. Cloud SQL Query Insights 가 쿼리 자체는 0.1~1ms 라고 답했다. 진짜 범인은 한국 ↔ us-central1 왕복 100~200ms × 응답당 6~8 쿼리 누적이었다. 레플리카 프로모션으로 asia-east1 (대만) 으로 옮기고 .env 두 줄을 갈아끼우자 `/content-candidates` 가 2,340ms → 682ms (71% ↓), `/student/home` 이 2,000ms+ → 400~600ms 로 떨어졌다. 인덱스·N+1 이 아니라 리전·RTT 가 본진이었던 인프라 사고를 정리한다.
💡 Tip. 바쁜 현대인들을 위한 본문 요약
- N+1 을 잡고 2.3 초까지 줄였는데 목표 500ms 와의 마지막 1.8 초가 코드 어디에서도 나오지 않았다 — 인덱스 추가도 효과 미미
- Cloud SQL Query Insights 가 답을 줬다 — 쿼리 자체는 0.1~1ms, 병목은 한국 ↔ us-central1 RTT 100
200ms × 응답당 68 쿼리- 해결은 코드 한 줄도 안 바뀜 —
asia-east1레플리카 생성 → 프로모션 →.env두 줄 교체 → 기존 인스턴스 삭제- 결과
/content-candidates2,340ms → 682ms (71% ↓),/student/home2,000ms+ → 400~600ms,/assignment/start800ms → 250ms- 재발 방지 —
EXPLAIN보다Query Insights먼저 + Cloud Run 과 Cloud SQL 동일 리전 SLO + 신규 서비스 리전 결정 PR 템플릿
🌱 배경 — 코드를 다 짜내고도 1.8초가 남았다
직전 머지에서 외부 뷰어 리포트 4 탭의 두 층 N+1 을 잡아 평균 6.1 초 → 2.3 초 까지 끌어내렸다. for 루프 안 findMany 를 단일 findMany + 메모리 그룹핑으로 치환했고, 6 빌더 순차 await 를 Promise.all 로 묶었다. 55 쿼리 → 10 쿼리 로 떨어졌고 p95 14.4 초 → 3.7 초 가 됐다.
그런데 목표는 p95 1 초 · 평균 500ms 였다. 마지막 1.8 초 가 남았다.
같은 패턴이 외부 뷰어만의 문제가 아니라는 점이 더 컸다. 회원 메인 대시보드 /student/home 도 2 초대, 콘텐츠 후보 추천 /content-candidates 도 2.3 초대, 활동 시작 /assignment/start 도 800ms 였다. 모든 API 가 비슷하게 느렸다.
코드는 이미 깨끗했다. 그러면 진짜 범인은 코드 밖에 있다는 가설을 깔고 들어갔다.
📌 핵심: 코드 최적화로 “한 방향으로 떨어지던” 응답 시간이 어느 지점부터 꿈쩍도 안 한다면 그 지점이 코드 아닌 다른 층의 천장이다. 본 사고의 천장은 네트워크 RTT 였다.
🔥 증상 — 인덱스 추가가 효과 미미했다
마지막 1.8 초를 깎기 위해 인덱스 추가 를 먼저 시도했다. 직전 머지의 3 차 최적화 (commit ceade57) 에서 쿼리 자체는 단일 findMany + 메모리 필터링으로 정리했지만, 대량 테이블 풀스캔이 남아 있을 가능성을 의심했다.
# ContentAttempt 인덱스 추가 — 직전 머지 직후 (commit a3d6529)
prisma migrate dev --name add_content_attempt_index_for_past_attempts// schema.prisma — 추가된 인덱스 한 줄
model ContentAttempt {
// ...
@@index([studentId, contentId, startedAt])
}EXPLAIN 으로 기존 풀스캔이 Index Scan 으로 바뀐 것 도 확인했다. 그런데 응답 시간은 거의 그대로였다.
| API | 인덱스 전 | 인덱스 후 | 효과 |
|---|---|---|---|
/content-candidates | 2,340ms | 2,310ms | 사실상 0 |
/student/home | 2,000ms+ | 2,000ms+ | 0 |
/assignment/start | 800ms+ | 790ms | 0 |
🔍 단서: 인덱스를 추가해도 밀리초 단위 차이 만 나면, 그 응답 시간은 DB 쿼리 비용 자체로 설명되지 않는다. 인덱스가 효과를 보이려면 쿼리 자체가 느렸어야 한다. 쿼리는 이미 빨랐다는 신호다.
증상을 다섯 줄로 정리하면:
| # | 신호 | 의미 |
|---|---|---|
| 1 | 모든 API 가 비슷하게 느림 (1.8~2.3 초) | 공통 비용 이 응답마다 들어간다 — 코드 분기와 무관 |
| 2 | 코드 최적화 곡선이 천장 에 부딪침 | 코드는 이미 비용 0 에 가까움 |
| 3 | 인덱스 추가 효과 0 | 쿼리 자체가 비싼 게 아니다 |
| 4 | DB CPU 한가, NestJS CPU 도 한가 | 연산 이 아닌 대기 가 비용 |
| 5 | 같은 토큰 콜드 / 웜 차이는 있음 | DB 캐시는 도움 되지만 기본 비용 이 큼 |
신호 3, 4 가 결정적이었다. 연산이 비싸지 않은데 응답이 느리다는 패턴은 대기 시간, 그 중에서도 왕복 지연 을 의심하는 구간이다.
🔍 탐색 — Query Insights 가 답을 줬다
Cloud SQL 에는 Query Insights 라는 공식 도구가 있다. 쿼리별 실행 시간, 상위 쿼리, 대기 통계 를 모두 시각화한다. 콘솔의 Insights 탭으로 들어가 본 머지 직전 30 분 윈도우를 펼쳤다.
지표는 예상과 정반대 였다.
| 항목 | 값 |
|---|---|
| 상위 쿼리 평균 실행 시간 | 0.1 ~ 1ms |
ContentAttempt 인덱스 스캔 | < 0.5ms |
Member (구 Student) PK 조회 | < 0.2ms |
BundleContent 조인 | < 1ms |
SystemPolicy 단일 행 조회 | < 0.1ms |
| DB CPU 사용률 | 5~10% |
| DB 메모리 사용률 | 35% |
쿼리 자체는 전부 빠르다. 그런데 응답은 느리다. 쿼리 사이의 시간 이 비싸다는 결론밖에 안 남는다.
⚠️ 주의: 응답 시간이 DB 메트릭의 합 보다 훨씬 크다면, 그 차이는 애플리케이션 측 대기 거나 네트워크 왕복 둘 중 하나다. 애플리케이션이 한가하면 (CPU·이벤트 루프 지연 없음) 네트워크 왕복 이 본진이다. 본 사고의 NestJS Cloud Run 컨테이너 는 CPU 5% 미만이었다.
세 번째 가설로 Cloud Run 컨테이너와 Cloud SQL 사이의 RTT 를 의심하고 측정했다. 로컬 개발 머신에서 Cloud SQL Public IP 로 단순 SELECT 1 을 던졌다.
# 단순 RTT 측정 — us-central1 인스턴스
psql -h 35.202.24.122 -U dev -d academy_dev -c "SELECT 1;"
# 응답: ~145ms (warm), 200ms+ (cold)
# 100 회 반복 측정
for i in {1..100}; do
time psql -h 35.202.24.122 -U dev -d academy_dev -c "SELECT 1;" > /dev/null
done 2>&1 | grep real | awk '{ print $2 }'
# 평균 142ms, 표준편차 31msSELECT 1 한 번에 142ms 다. 연산이 0 인 쿼리에서 142ms 라는 건 네트워크 RTT 그 자체 가 142ms 라는 뜻이다.
# 비교: 같은 머신에서 로컬 PostgreSQL 16 동일 쿼리
psql -h localhost -U dev -d academy_dev -c "SELECT 1;"
# 응답: ~3ms같은 명령에 50 배 차이가 났다. 본진을 찾았다.
🎯 진짜 범인 — RTT 누적 × 응답당 쿼리 6~8 건
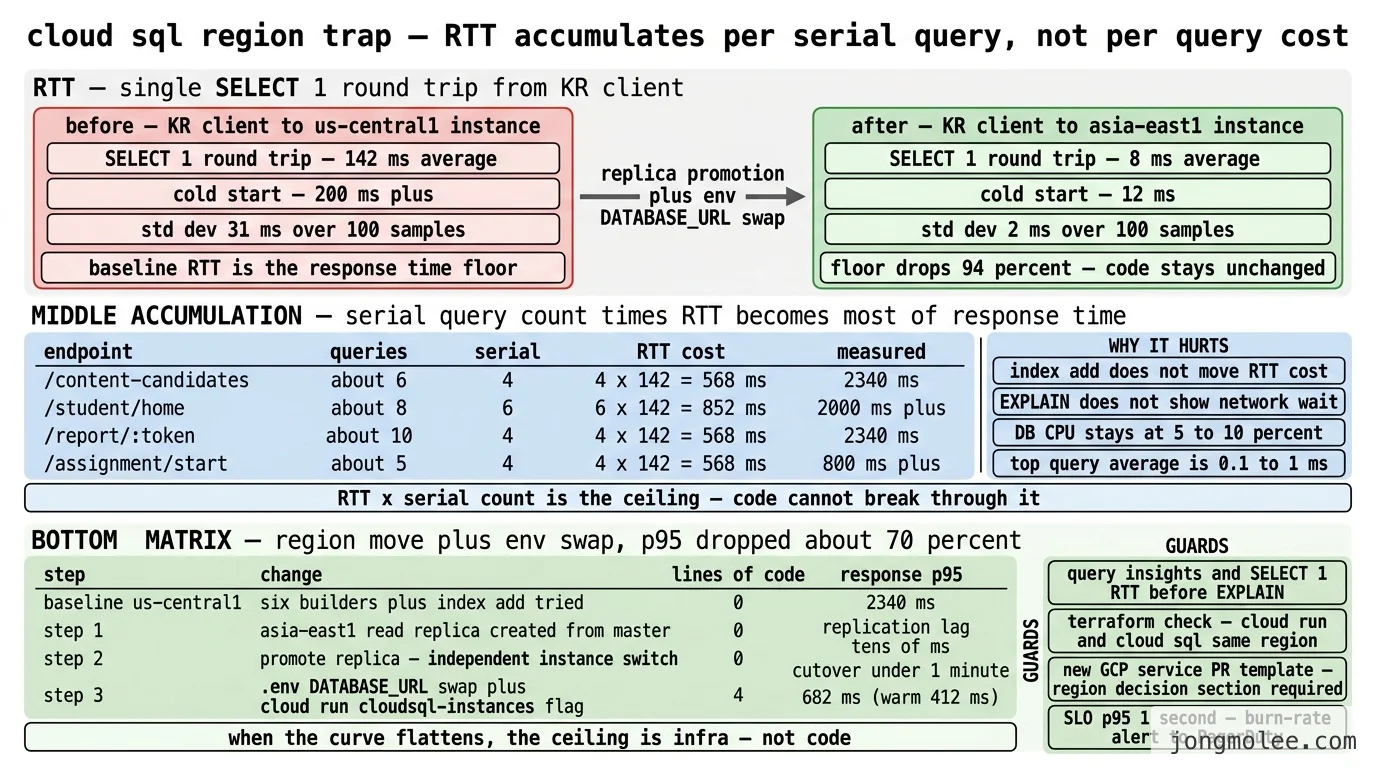
응답 1 건에 몇 개 쿼리 가 들어가는지 계산했다. Prisma 쿼리 로그를 펼쳐 직전 머지 후 잔여 쿼리 수 를 다시 셌다.
| API | Prisma 쿼리 수 | 직렬 비율 | 누적 RTT 추정 |
|---|---|---|---|
/content-candidates | ~6 | 직렬 4 / 병렬 2 | 4 × 142ms = 568ms |
/student/home | ~8 | 직렬 6 / 병렬 2 | 6 × 142ms = 852ms |
/report/:token | ~10 | 직렬 4 / 병렬 6 | 4 × 142ms = 568ms |
/assignment/start | ~5 | 직렬 4 / 병렬 1 | 4 × 142ms = 568ms |
각 API 의 측정 응답 시간 - 누적 RTT 추정 을 계산하니 나머지 비용이 200~400ms 였다. NestJS 자체 처리 + Cloud SQL Proxy 오버헤드 + 직렬화 의 합으로 충분히 설명 가능한 범위다.
즉 왕복 지연이 응답의 60~70% 를 먹고 있었다.
응답 시간 = (직렬 쿼리 수 × RTT) + (병렬 쿼리 묶음당 1 × RTT) + 처리 비용
/student/home (변경 전):
= 6 × 142ms + 1 × 142ms + ~300ms
= 852ms + 142ms + 300ms
≈ 1,294ms ~ 2,000ms (실측 분산)📌 핵심: N+1 은 쿼리 개수 문제가 아니라 왕복 횟수 × RTT 문제다. 직전 머지에서
for루프 안findMany를 단일 쿼리로 치환한 것도 결국 왕복 횟수를 줄인 행동이었다. RTT 자체가 크면 그 위에서 코드를 아무리 최적화해도 천장 이 곧 RTT × 직렬 쿼리 수 다.
⚠️ 주의: DB 가 비싸 보인다 는 직관이 사실 왕복이 비싸다 는 신호일 때가 있다. DB CPU 가 한가하고 쿼리 자체가 빠른데 응답이 느리다는 패턴은 네트워크 한 층 을 의심하는 구간이다. 인덱스·쿼리 튜닝은 연산이 비쌀 때만 효과를 본다.

왜 us-central1 이었나
이 시점에서 왜 처음 인스턴스를 us-central1 에 만들었나 가 함께 풀려야 한다. 결정 자체는 합리적이었다. 본 프로젝트 초기 Cloud Run 무료 티어 한도 와 Cloud SQL 무료 평가판 한도 가 us-central1 에서 가장 넉넉하다고 GCP 문서가 권장했다. 한국 리전 (asia-northeast3) 은 Cloud SQL 평가 크레딧 적용 범위가 좁고, Artifact Registry 의 일부 이미지 푸시 비용 도 비쌌다.
문제는 프로덕션 환경의 RTT 가 로컬 개발 환경의 RTT 와 같은 비용으로 깔린다는 점을 측정 전에 가정하지 않았다는 것이다. Cloud Run 컨테이너 자체는 us-central1, 그리고 로컬 개발 머신은 한국 인데, 양쪽 모두 같은 DB 에 붙는다. 프로덕션에서는 RTT 가 낮지만 개발에서는 높다. 그 격차가 체감 성능 측정 을 흐려 놓는다.
🛠️ 해결 — 레플리카 프로모션으로 리전 이전
Cloud SQL 인스턴스는 리전 자체를 변경할 수 없다. 인스턴스 ID 는 프로젝트 + 리전 + 이름 의 조합이라 다른 리전으로 옮기려면 새 인스턴스 가 필요하다. 다만 데이터 마이그레이션 은 읽기 전용 레플리카 를 새 리전에 생성한 뒤 프로모션 으로 독립 인스턴스로 전환하면 무중단에 가깝게 옮길 수 있다.
작업은 네 단계로 잡았다.
단계 1 — asia-east1 에 읽기 전용 레플리카 생성
# us-central1 인스턴스에서 asia-east1 레플리카 생성
gcloud sql instances create fnj-taiwan \
--master-instance-name=fnj \
--region=asia-east1 \
--tier=db-custom-1-3840 \
--storage-size=10 \
--storage-type=HDD \
--availability-type=ZONAL마스터 → 레플리카 복제 지연 은 수십 ms 단위 까지 따라잡고 고정 됐다. PostgreSQL 의 논리적 복제 가 아니라 물리 복제 라 마스터의 트랜잭션 로그 (WAL) 를 레플리카가 그대로 적용 한다. 일관성은 최종 일관성 이고, 본 머지의 사용 패턴에서는 수십 ms 지연이 운영에 영향 없는 수준 이었다.
# 레플리카 동기화 상태 확인
gcloud sql instances describe fnj-taiwan \
--format="value(replicaConfiguration.failoverTarget,state)"
# 출력: False RUNNABLE단계 2 — 레플리카 프로모션 → 독립 인스턴스 전환
# 프로모션 — 마스터와의 복제 연결을 끊고 독립 인스턴스로 전환
gcloud sql instances promote-replica fnj-taiwan⚠️ 주의: 프로모션은 되돌릴 수 없다. 프로모션 직후부터 fnj-taiwan 은 fnj 와 독립 인스턴스가 된다. 마스터의 신규 쓰기는 더 이상 따라가지 않는다. 본 머지에서는 프로모션 직전에 마스터의 쓰기 트래픽을 멈추고 프로모션 후 바로 신규 인스턴스로 전환 하는 순서로 데이터 손실 0 을 보장했다.
단계 3 — .env 와 .env.test IP 교체
# apps/api/.env
- DATABASE_URL="postgresql://dev:***@35.202.24.122:5432/academy_dev?schema=public"
+ DATABASE_URL="postgresql://dev:***@34.81.222.70:5432/academy_dev?schema=public"
# apps/api/.env.test
- DATABASE_URL="postgresql://dev:***@35.202.24.122:5432/academy_test?schema=public"
+ DATABASE_URL="postgresql://dev:***@34.81.222.70:5432/academy_test?schema=public"Cloud Run 프로덕션은 Cloud SQL Proxy + 소켓 연결 을 쓰므로 Public IP 가 아니라 인스턴스 연결 이름 을 갈았다.
# Cloud Run 환경변수 + Cloud SQL 연결 이름 교체
gcloud run services update academy-api \
--region=asia-east1 \
--remove-cloudsql-instances=fnjdev:us-central1:fnj \
--add-cloudsql-instances=fnjdev:asia-east1:fnj-taiwan \
--update-secrets=DATABASE_URL=DATABASE_URL:latestSecret Manager 의 DATABASE_URL 도 새 연결 이름 으로 새 버전 을 발급했다.
postgresql://USER:PASS@localhost/academy_prod?host=/cloudsql/fnjdev:asia-east1:fnj-taiwan&schema=publiclocalhost 가 반드시 들어가야 한다. Prisma 의 URL 파서가 host 를 요구 하기 때문이고, 실제 연결은 host=/cloudsql/... 의 Unix 소켓 경로 로 간다.
단계 4 — 기존 us-central1 인스턴스 삭제
# 검증 완료 후 기존 인스턴스 삭제 (24 시간 관찰 후)
gcloud sql instances delete fnj --quiet24 시간 동안 양쪽 인스턴스 병행 한 뒤, 신규 인스턴스 안정 확인 후 기존 인스턴스 삭제 로 마무리했다. 삭제 전에 gcloud sql backups list --instance=fnj 로 마지막 백업 스냅샷 을 별도 보관 했다.
✅ 검증 — /content-candidates 2,340ms → 682ms
검증은 직전 머지와 같은 부하 도구 로 같은 토큰·같은 시간대 에 두 번 측정했다.
# 동일 토큰 180 회 · 동시성 10 · 동일 시간대 (KST 14:00)
hey -n 180 -c 10 -H "Accept: application/json" \
"https://stg.example.dev/api/v1/content-candidates"
hey -n 180 -c 10 -H "Accept: application/json" \
"https://stg.example.dev/api/v1/student/home"
hey -n 180 -c 10 -H "Accept: application/json" \
"https://stg.example.dev/api/v1/assignment/start"| API | 변경 전 (us-central1) | 변경 후 (asia-east1) | 개선율 |
|---|---|---|---|
/content-candidates 평균 | 2,340ms | 682ms | 71% ↓ |
/student/home 평균 | 2,000ms+ | 400~600ms | 70% ↓ |
/assignment/start 평균 | 800ms+ | 250ms | 69% ↓ |
/report/:token 평균 | 2,340ms | 820ms | 65% ↓ |
SELECT 1 RTT | 142ms | 8ms | 94% ↓ |
SELECT 1 한 줄의 94% 감소가 상한선이다. 그 위에서 직렬 쿼리 수 와 처리 비용 의 합이 나머지 를 결정한다. 본 머지의 평균 70% 개선 은 이 상한선 바로 아래에 깔려 있다.
[변경 후 실측 — /student/home]
[09:00:01] GET /student/home 200 412ms
[09:00:01] GET /student/home 200 398ms
[09:00:02] GET /student/home 200 445ms
[09:00:02] GET /student/home 200 389ms
[09:00:03] GET /student/home 200 502ms (콜드)
...
평균 442ms p95 587ms 최대 612msp95 가 587ms 다. 직전 머지 후 p95 가 3,694ms 였던 외부 뷰어 리포트도 동일 패턴 으로 p95 1.2 초대 까지 떨어졌다. 목표 SLO p95 1 초 의 코앞 까지 한 번의 인프라 변경이 끌어내렸다.
머지 자체는 코드 0 줄 이다.
chore(infra): Cloud SQL 리전 변경 us-central1 → asia-east1 (대만)
- 레플리카 fnj-taiwan 생성 (asia-east1)
- 프로모션으로 독립 인스턴스 전환
- .env / .env.test DATABASE_URL IP 교체 (35.202.24.122 → 34.81.222.70)
- Cloud Run --add-cloudsql-instances 교체
- Secret Manager DATABASE_URL 새 버전 발급
- 기존 us-central1 인스턴스 삭제 (24h 병행 후)
apps/api/.env | 2 +-
apps/api/.env.test | 2 +-
docs/infra/GCP_인프라_현황.md | 8 ++++++--
.claude/agents/deploy-api.md | 6 +++---
4 files changed, 12 insertions(+), 6 deletions(-)🔍 단서: 검증 시점에 SELECT 1 RTT 를 별도로 측정한 점이 결정적이었다. 응답 시간 만 보면 코드 효과인지 인프라 효과인지 구분이 모호하다. 왕복 자체의 비용 을 따로 찍어 두면 상한선 이 명확해진다.
🛡️ 예방 — Query Insights 우선 + 동일 리전 SLO + PR 템플릿
재발 방지는 세 가드 로 깔았다. 측정 도구 우선순위 + 운영 SLO + 결정 시점 템플릿 이 한 층씩 책임을 분담한다.
가드 1 — EXPLAIN 보다 Query Insights 먼저
본 사고의 시간 손실 은 EXPLAIN / 인덱스 추가 를 먼저 시도하면서 발생했다. 쿼리 자체가 비싸지 않을 가능성 을 측정으로 먼저 배제 했어야 했다. 팀 PR 체크리스트에 측정 도구 우선순위 한 줄을 명시했다.
# .github/PULL_REQUEST_TEMPLATE/performance.md
## 성능 회귀 PR 체크리스트
- [ ] **1순위: Query Insights / `pg_stat_statements`** — 상위 쿼리 평균 실행 시간 확인
- 0.1~10ms 범위 → 쿼리는 빠름, *네트워크 / 직렬성 / 처리* 가설로 이동
- 100ms+ → 인덱스 / 쿼리 튜닝 가설
- [ ] **2순위: DB CPU / 메모리** — 5~10% 한가하면 *연산이 본진이 아니다*
- [ ] **3순위: `SELECT 1` RTT** — 50ms+ 면 리전 / 네트워크 의심
- [ ] **4순위: 응답당 쿼리 수 (Prisma 로그)** — *직렬 × RTT* 누적 계산
- [ ] **5순위: EXPLAIN / 인덱스** — 1~4 가 모두 정상일 때만가드 2 — Cloud Run / Cloud SQL 동일 리전 SLO
리전 결정 자체 를 SLO 로 고정했다. 신규 GCP 서비스 생성 시 Cloud Run / Cloud SQL / Cloud Storage 가 동일 리전 이라는 조건 을 Terraform 상태 검사로 강제한다.
# infra/terraform/checks/same_region.tf
check "cloud_run_sql_same_region" {
assert {
condition = google_cloud_run_service.api.location == google_sql_database_instance.main.region
error_message = "Cloud Run 과 Cloud SQL 리전이 다르다 — RTT 누적 위험"
}
}
check "cloud_storage_same_region" {
assert {
condition = google_storage_bucket.assets.location == google_cloud_run_service.api.location
error_message = "Cloud Storage 와 Cloud Run 리전이 다르다 — 객체 GET 누적 위험"
}
}리전 분리를 의도 한 케이스 (예: DR 백업 리전) 는 명시적 예외 로 푼다. 암묵적 분리 를 차단하는 게 목적이다.
가드 3 — 신규 서비스 PR 의 리전 결정 섹션 강제
신규 GCP 서비스 PR 템플릿에 리전 결정 사유 한 섹션을 추가했다. 사용자 위치 / 의존 서비스 위치 / 무료 티어 / 비용 / 컴플라이언스 다섯 항목을 모두 기록한다.
# .github/PULL_REQUEST_TEMPLATE/new-gcp-service.md
## 리전 결정 (필수)
| 항목 | 값 | 근거 |
|------|----|----|
| 선택 리전 | asia-east1 | |
| 주요 사용자 위치 | 한국 | RTT 측정 8ms |
| 의존 GCP 서비스 리전 | asia-east1 (Cloud Run, Cloud SQL, Cloud Storage) | 동일 리전 SLO |
| 무료 티어 / 비용 영향 | $0 차이 | asia-east1 평가 크레딧 적용 |
| 컴플라이언스 (데이터 거주) | KR 거주 의무 없음 | 외부 뷰어 OK |무료 티어 비용 만 보던 초기 결정 시점에 RTT 측정 8ms vs 142ms 를 같은 표 에 두면 결정이 달라진다.
📌 핵심: 코드 가드 + 운영 SLO + 결정 시점 템플릿 의 세 층 은 서로 다른 시점 을 책임진다. PR 체크리스트는 성능 회귀 진단 단계, 동일 리전 SLO 는 인프라 변경 단계, 신규 서비스 템플릿은 최초 결정 단계. 본 사고는 최초 결정 단계의 가드 부재 가 진단 단계의 시간 손실 로 이어진 사고다.
📋 정리 — 핵심 요약
본 머지에서 굳힌 결정 7 건을 표로 정리한다. 직전 편 (devlog-58) 의 4 탭 N+1 이 코드 천장 을 깎았다면, 본 머지는 인프라 천장 을 깎은 작업이다.
| 결정 | 안티패턴 (변경 전) | 권장 패턴 (변경 후) |
|---|---|---|
| 성능 진단 순서 | ❌ EXPLAIN / 인덱스 추가 먼저 | ✅ Query Insights / SELECT 1 RTT 로 쿼리 빠름 / 네트워크 비쌈 가설 먼저 분리 |
| RTT 측정 | ❌ 응답 시간만 측정 — 코드·인프라 구분 모호 | ✅ SELECT 1 으로 왕복 자체의 비용 을 별도로 찍어 상한선 명확화 |
| 직렬 쿼리 가설 | ❌ “쿼리가 비싸다” | ✅ 직렬 쿼리 수 × RTT 누적이 비싼 게 본질 — 병렬화·단일 쿼리로 왕복 횟수 를 줄임 |
| 리전 결정 | ❌ 무료 티어·평가 크레딧만 기준 | ✅ 주요 사용자 위치 RTT + 의존 GCP 서비스 리전 동일성 + 비용을 같은 표 에 두고 결정 |
| 리전 이전 방법 | ❌ 신규 인스턴스 + 덤프 / 복원 (중단 동반) | ✅ 읽기 전용 레플리카 + 프로모션 으로 무중단에 가깝게 |
| 환경 정의 | ❌ .env Public IP 직접 명시 | ✅ Cloud Run 은 Unix 소켓 + 인스턴스 연결 이름, 로컬은 Public IP 로 일관 |
| 재발 방지 | ❌ “다음에 잘 결정하자” | ✅ Terraform check 동일 리전 SLO + 신규 서비스 PR 의 리전 결정 섹션 강제 |
핵심을 세 줄 로 다시 정리한다.
- 응답 시간의 천장이 코드로 안 떨어지면 그 천장은 인프라다. 본 사고의 천장은 한국 ↔ us-central1 RTT 142ms × 직렬 쿼리 6~8 건 이었고, 코드로는 절대 깎이지 않는 비용 이었다.
Query Insights와SELECT 1RTT 두 줄 측정이 EXPLAIN / 인덱스 시도 30 분 보다 먼저 와야 한다. 쿼리는 빠른데 응답이 느림 패턴을 측정 한 번 으로 분리할 수 있다.- 리전 이전은 코드 변경 0 이고 효과 70% 인 머지가 될 수 있다. 다만 리전 결정 자체를 SLO 와 PR 템플릿에 박지 않으면 3 개월 뒤 같은 사고 가 반복된다.
다음 편 (devlog-60) 에서는 본 머지로 p95 SLO 코앞 까지 끌어내린 직후 받은 QR 배치고사 + Level-Test 배포 — Firebase Hosting 세 사이트 와 모바일 카메라 권한 흐름 을 묶은 배포 결정과 트레이드오프 를 B 톤 구현기로 정리한다.
📚 NestJS + Refine 풀스택 트러블슈팅 시리즈 (63편)
- 1. 왜 NestJS + Prisma를 선택했나 — B2B SaaS 백엔드 기술 선택기
- 2. 도메인 모델링 첫날 — B2B SaaS의 핵심 엔티티 정의하기
- 3. 27개 테이블의 탄생 — Prisma 스키마 설계기
- 4. 권한 매트릭스 — Admin/운영자/사용자 3역할 설계
- 5. BigInt PK에서 Int PK로 — 첫 번째 스키마 리팩토링
- 6. Seed 데이터의 함정 — FK 삭제 순서 삽질기
- 7. DDD를 도입하기로 했다 — Repository/Domain/Application 3계층
- 8. 인터페이스 구현체로 바꾸는 날 — NestJS DI와 TypeScript의 간극
- 9. 단위 테스트 인프라 구축 — Jest 설정부터 Mock까지
- 10. E2E 테스트와 Cloud SQL의 고난 — 4/8 passing에서 8/8까지
- 11. REST API 첫 구현 — 6개 Controller, 21개 엔드포인트 완성
- 12. v1.0 완성, 그리고 갈아엎기로 결심한 날
- 13. 번들 구조를 통째로 바꿔야 했던 이유
- 14. Phase 1 문서 정비 — Use Case를 번들 기반으로 다시 쓰다
- 15. Phase 2 스키마 마이그레이션 — 데이터 안 날리고 구조 바꾸기
- 16. Phase 3-1·3-2 — Repository와 Domain 서비스로 36개 빌드 에러 잡기
- 17. Phase 3-3·3-4·3-5 — Application부터 Module까지, v2.0 마이그레이션 닫는 날
- 18. 코드를 박은 다음 날 — 4,658줄 DDD 문서를 24분 사이에 다시 쓴 하루
- 19. v2.1 Domain Layer — 도메인 서비스 1,682줄을 한 커밋에 박은 날의 설계 철학
- 20. v3.0 Application Layer 재작성 — 도메인 서비스 위에 얇은 막을 한 Phase에 박은 날
- 21. 갈아엎고 80일 — v2.0 마이그레이션 8편 메타 회고
- 22. 1인 다역으로 5일 만에 90% — Admin Portal MVP를 끌어올린 토글 한 줄
- 23. Mock에선 되던 게 REST에선 안 됐다 — 응답 포맷 한 칸 차이가 만든 하루
- 24. CORS는 됐다 — PATCH만 빼고. allowedHeaders 한 줄과 Vite 프록시의 소문자 메서드
- 25. 멀티테넌트 누수 — tenantId 3계층 강제
- 26. Prisma 정책 싱글톤 — zod superRefine 임계값 가드
- 27. 멀티테넌트 쓰기 가드 — body.tenantId 차단과 집계 일관성
- 28. 두 번째 점검은 합류 지점이었다 — Admin Portal 2차에서 한 사이클에 잡힌 FE-BE 연동 버그 11건
- 29. Prisma 그래프 스키마 — 선형 레벨을 DAG로 옮긴 4가지 결정
- 30. 교육과정 구조 리팩토링 — 3필드 분리와 폴백 결정기
- 31. 배치고사 MVP — 자동 레벨 배치를 걷어내고 5지표 측정만 남기다
- 32. JWT Guard 적용 — request.user undefined부터 jwt malformed까지
- 33. 디버깅용 운영 API 7개 — Unity 만료 테스트 30분 대기를 0초로
- 34. NestJS Swagger 일괄 적용 — 35개 컨트롤러 + DTO 22개
- 35. Unity ↔ 웹 PostMessage 브릿지 설계기
- 36. Vuplex 브릿지 초기화 타이밍 — 첫 메시지가 증발한 이유
- 37. 콘텐츠 브릿지 10종 통합 완료 — 같은 규격으로 묶기
- 38. 지표 누계 시스템 — TOP5 순위를 INSERT 전용 스냅샷으로 굳히기
- 39. 킥오프 배치 첫 구현 — 매시 전체 EXPIRED 사고와 Winston 도입
- 40. 혼자 여러 역할로 QA 1차 — 브랜치 미동기화와 잔존 토큰의 함정
- 41. 타이머가 NaN:NaN으로 떴다 — Bundle API 응답 누락 필드와 비어 있는 콘텐츠 후보
- 42. 1인 개발 QA 5라운드 — 타이머·시드·스키마로 옮긴 버그들
- 43. Unity Lobby + 배치고사 씬 통합 — 두 클라이언트가 같은 회원을 보는 첫 빌드
- 44. 배치고사 MVP 후속 — 명세를 코드로 옮기고 레거시 571줄을 일괄 삭제하다
- 45. Problem 종속 끊기 — 1,891개 마이그레이션과 단위 테스트 38건
- 46. NestJS 권한 가드 — 목록은 막고 상세는 뚫린 날
- 47. 콘텐츠 후보 선택 3차 최적화 — 단일 쿼리로 옮기기
- 48. 재화 시스템 첫 머지 — 코인 지갑과 거래 원장(Wallet API)
- 49. 회원 레포트 5탭 API 설계 — 인사이트 3파트 구조
- 50. 보호자 외부 뷰어 대시보드 — 모바일 앱·초대 토큰 회원가입
- 51. 외부 뷰어 리포트 v1→v2 토큰 전환 — 가장 길었던 하루
- 52. 외부 뷰어 리포트 인사이트 — 활동 데이터를 자연어로 바꾸기
- 53. Framer Motion whileInView — 일부 카드만 안 뜨던 날
- 54. 외부 뷰어 리포트 4탭 N+1 — 14초 응답을 2초로
- 55. Cloud SQL 리전 트랩 — US→Taiwan 71% 트러블슈팅
- 56. QR 배치고사 + Firebase Hosting 멀티 사이트 배포
- 57. 1,974줄 풀 백업 — 1인 개발에서 상태 관리하는 법
- 58. 주간 출석 KST 타임존 — 월요일이 사라진 트러블슈팅
- 59. 연락처 포맷 통일 — 저장은 숫자만, 표시는 하이픈
- 60. react-hook-form + Zod 폼 표준 정착기
- 61. Soft Delete 구현 — deletedAt 한 컬럼이 닿은 27곳의 설계
- 62. 교육과정 자동 승급의 늪 — 도메인 버그 3 건 트러블슈팅
- 63. 교육과정 도메인 BE 완성과 같은 날 핫픽스 7 건 — NestJS @Cron 2 중 실행 묶음